

Data modeling is the process of Data flowcharting. Designers while developing a new or different database structure take the first step as an illustration of data flows into and out of the database structure. Data Modeling Interview Questions provide us with an efficient base to develop a basic understanding of how to get started in the field of data modeling. To effectively meet the data flow needs, we use this flow diagram to define the properties of the data formats, structures, and database handling functions.
The data model continues to exist after constructing and making the database available, serving as the basis for the documentation and rationale behind the database’s creation and the architecture of its data flows. As per the title, we will discuss the most commonly asked Data Modeling Interview Questions in this article and work through the Basic and Intermediate levels.
To propel in the field of data modeling certainly, one can explore this course of Data Science.
Top 20 Data Modeling Interview Questions And Answers
Let’s have a look at the best 20 Data Modeling interview questions and Answers based on the different levels.
Basic Data Modeling Interview Questions
Q1. What is Data Modeling?
Ans- Data modeling is the process of building a data representation that may be preserved in a database. It is a pictural representation of data objects, containing their connections and rules.
Q2. What is Normalization in Data Modeling?
Ans-Database normalization is a vital process in database design. It involves organizing data to reduce redundancy and dependency by breaking it into separate tables and establishing relationships between them. Certainly, this minimizes anomalies and inconsistencies.

Q3. What are the benefits of data modeling?
Ans- Data modeling helps professionals from various domains altogether to understand the relationships between data objects in a Data Warehouse or database, facilitating data mapping and improving communication between different departments.
Q4. What is a table in Data Modeling?
Ans- When we examine a table, we see that a grid of rows and columns structures the data. The columns, also known as fields, display vertically, with each column representing a specific type of information. On the other hand, rows also referred to as records or tuples, run horizontally and contain a complete set of data related to an individual entity.
Q5. What are the three types of data models?
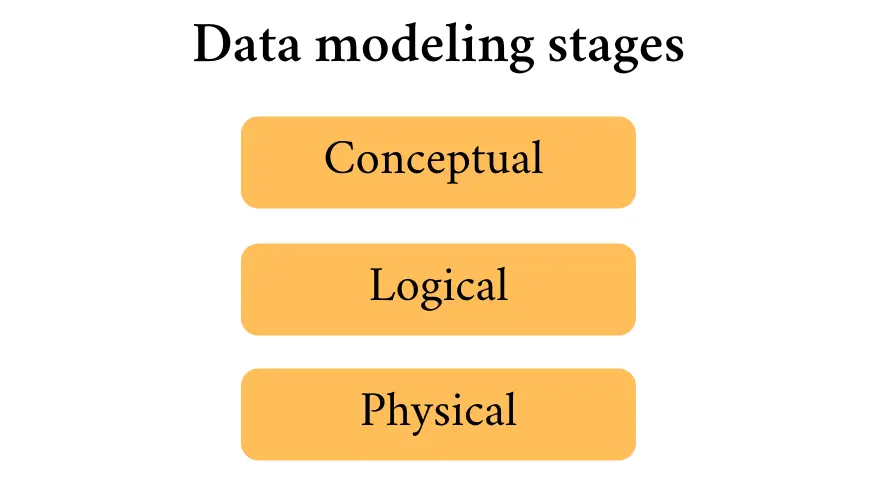
Ans- The three types of models:
Conceptual database – This model focuses on a high-level, user’s view of the data in question.
Logical data models – logical data models straddle between physical and theoretical data models, allowing the logical representation of data to exist autonomously in physical storage.
Physical data models – This is where the framework or schema describes how data is physically stored in a database.
Q6. How does the data modeler use normalization in data modeling?
Ans- The purposes of normalization are to remove useless or redundant data Reduce data complexity, and ensure relationships between the tables in addition to the data residing in the tables. Please ensure that all data dependencies are checked and that the data is stored appropriately.
Q7. What is denormalization and its purpose?
Ans- Denormalization is the process of adding redundant data to a previously normalized database, which improves read performance but may decrease write performance.
Q8. What is ERD and its meaning?
Ans- ERD stands for Entity Relationship Diagram, and it is a logical entity representation that illustrates the relationship between the entities entailed within the boxes, with arrows implying relationships.
Q9. What’s the definition of a surrogate key in data modeling?
Ans- This, also known as the primary key, enforces numerical attributes. The surrogate key replaces natural keys. Data modelers use surrogate keys to identify data and speed up queries. Surrogate keys are special codes that make finding information and running database searches easier.
Q10. What is enterprise data modeling?
Ans- The data modeling described here is a comprehensive framework that includes all the necessary data entries required to effectively support the operations and activities of an enterprise. Moreover, you can gain all skills to clear interview with the help of a Data Science Certification in India.
Intermediate Data Modeling Interview Questions.
Q11. What are the critical relationship types found in data modeling? Describe them.
Ans- The main relationship types are:
1. Identifying -In a database, a relationship line connects parent and child tables. A thick line signifies an identifying relationship when the reference column of a child table is part of the table’s primary key. A dotted line indicates a non-identifying relationship when the reference column is not part of the primary key.
2. Non-identifying -If a child table’s reference column is not part of the primary key, a dotted line connects the tables to indicate a non-identifying relationship.
3. Self-recursive – A recursive connection is a column in a table that references the primary key of the same table.
Q 12. Can you mention the most common errors a data modeler can potentially face in data modeling?
Ans- These are the most common faults observed during data modeling.
1. Building broad data models – When there are more than 200 tables, the data model becomes increasingly complex, which increases the likelihood of failure.
2. Unnecessary surrogate keys- Surrogate keys should only be used when the native key cannot serve as the primary key.
3. The purpose is lacking – Sometimes users may not be aware of a business’s objectives or goals. It’s difficult to create a specific business model if the data model doesn’t have a workable understanding of the company’s business model.
Q13. Explain two different design schemas.
Ans- The two design schemas are altogether the Star Schema and the Snowflake Schema. “Multiple dimension tables capture the star schema as a central fact table”. This schema is correspondingly used to organize data in a way that enables efficient query and analysis. Certainly, A snowflake schema is similar, except that the level of normalization is higher, “A snowflake schema is a database schema that evolves with certain tables connected to other tables through various kinds of relationships, providing a structure like a snowflake.”
Q14. Explain Data Mart.
Ans- A data mart is an established form of data warehouse that specializes in a single function of each company. Certainly, accepts data from various transactional systems, facilities, and external sources. Data marts accept data from a variety of transactional approach systems, other data facilities, and external sources.
Q15. What is Granularity in Data Modeling?
Ans- Granularity is dictating as high or low. High-granularity data at length contains transaction-level data. Low granularity refers to data that contains only low-level information, such as the one found in fact tables.
Q16. What is Data Sparsity, and its impact aggregation?
Ans- This defines the data we have for a model’s specified dimension or entity. Certainly, storing insufficient information in the dimensions and needing more space for these aggregations results in an oversized, cumbersome database.
Q17. Distinguish between Subtype and Supertype entities.
Ans- Entities are albeit, divided into smaller sub-entities based on specific features or characteristics. Additionally, a Sub-entity refers to a subtype entity that has its unique attribute. Certainly, a common attribute shared by all entities is placed in a higher entity known as a supertype entity.
Q18. Give a brief about the context of Data Modeling and its importance in METADATA.

Ans- Metadata is information about data. Data modeling covers details such as types of data, purpose, and users. By providing a complete picture of the data, metadata helps organizations manage the data effectively.
Q19) What are Recursive Relationships and how do we rectify them?
Ans- Recursive relationships happen when something has a connection with itself. Correspondingly, if a doctor becomes a patient at the same health center, a recursive relationship is created. We need to add a foreign key linking each patient’s record to the health center’s number.
Q20) What is a Junk Dimension in Data Modeling?
Ans- This is a table consisting of low-cardinality attributes such as indicators and flags. A single abstract dimension table is certainly a merge and extraction of Indicators and flags. Eventually, Data warehouses often use a technique called Rapidly Changing Dimensions. Besides, they use a specific tool to start the process.
Data Modeling Interview Questions- Henry Harvin’s Data Science Professional Course
If after reading this article “DATA MODELING INTERVIEW QUESTIONS AND ANSWERS” if you’re still not sure about the course you are in search of, consider registering for Henry Harvin’s Data Science Course. And certainly, You’ll comprehend a manager’s role in developing and executing information systems. Besides explaining the most widely used data science software in contemporary businesses, we will cover the fundamentals of data science technology. Web developers as well as IT engineers, architects, developers, administrators, and executives in IT service management would benefit greatly from this training.
In addition to a free one-year membership, the course offers training, projects, internships, certification, placement, e-learning, masterclasses, and hackathons. Especially professionals with over fifteen years of expertise in the field would be your teachers.
Conclusion
Data model results serve as both a manual for using the data and a structure for relationships between data components within a database. Basically, A fundamental component of analytics and software development is data models. Data modeling interview questions correspondingly provide scholars with a basic understanding of the course and potential interview questions. Certainly, these data modeling interview questions offer an appropriate technique to define and Structure Database Information uniformly across platforms, allowing applications to share data.
Recommended Reads
- Top 10 Data Science Courses In India with Placement
- Best Data Science Courses Online in 2023
- Top 5 Data Science Courses In Saudi Arabia
- Top 5 Data Science Projects for Beginners in 2024
- How To Learn Data Science In 2024
FAQs
Q1. What is the limitation of data modeling?
Ans -Data models can be inflexible and complex, additionally making it difficult for stakeholders to provide input or collaborate effectively.
Q2. What is the time series algorithm?
Ans – The time-series algorithm is a series of predicting the continuous value of data in a table. E.g.- the performance of one employee can forecast the profit or loss.
Q3. What are the five steps of data modeling?
Ans – The stages of the software development life cycle include requirements analysis, conceptual modeling, logical modeling, physical modeling, maintenance, and optimization.
Q4. Why is data modeling important?
Ans- The data model helps in creating a simplified, logical database that eliminates redundancy, reduces storage requirements, and enables efficient retrieval.
Q5. What is a quality data model?
Ans – Data models need to be easy to read and understand. Certainly, to avoid confusing your users, use simple structures and avoid unnecessary details.







{kind=link}